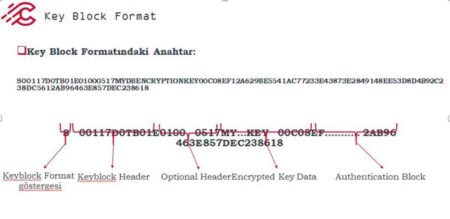
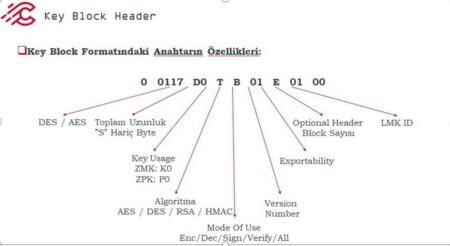
Facebook, kullanıcıların haber akışlarında paylaştığı politik içerik miktarını azaltmaya çalışıyor. Sosyal medya devinin söz konusu girişimi, şirketin algoritmalarının sorunlu olabileceği ihtimalinin sessiz bir şekilde onaylandığı anlamına geldiği düşünülüyor.
Sosyal medya algoritmaları, bir başka deyişle “içeriğe karar verirken bilgisayarların izlediği prosedürler” büyük ölçüde insanların bu kararları alma noktasındaki davranışlarına dayanıyor. İnsanlar beğenmek, yorum yapmak ya da paylaşmak suretiyle etkileşimde bulunduğu içerikler için özellikle fırsat kolluyor.
KALABALIKLARIN BİLGELİĞİ VARSAYIMI
Bu algoritmalarda sayıca kalabalık olanların bilgeliğinden faydalanmak anlaşılır bir durum. Ancak aynı zamanda sosyal medya şirketlerinin pratikte bunu nasıl yaptıkları konusunda önemli tuzaklar da bulunuyor.
“Kalabalıkların bilgeliği” kavramı, başkalarının eylemlerinden, görüşlerinden ve tercihlerinden gelen sinyalleri kılavuz olarak kullanmanın yerinde kararlara yol açacağını varsayar. Örneğin, toplu tahminler bireysel tahminlerden daha doğru çıkar. Kolektif zekâ, finansal piyasaları, spor etkinliklerini, seçimleri ve hatta salgınları tahmin etmede kullanılıyor.
HERKES KOŞMAYA BAŞLARSA SEN DE KOŞ
Örneğin, “Herkes koşmaya başlarsa, sen de koşmaya başlamalısın” görüşünün arkasında önemli bir motivasyon kaynağı bulunuyor. Neticede biri bir aslanın geldiğini görmüş olabilir ve bu durumda koşmak hayat kurtarabilir. Bir başka ifadeyle bazı şeyleri neden yaptığını bilmiyor olabilirsin ama soruları daha sonra sormak akıllıca bir davranış.
Beynimiz, çevreden ipuçları alır ve bu sinyalleri hızlı bir şekilde kararlara dönüştürmek için basit kurallar kullanır: Kazananın peşinden gitmek, çoğunluğu takip etmek komşun ne yapıyorsa onu yapmak gibi. Bu kurallar “genel durumlarda” oldukça iyi iş görür zira sağlam varsayımlara dayanmaktadır.
Teknoloji, çoğu insanın tanımadıkları çok daha fazla sayıda başka insanlardan gelen sinyallere erişmelerini sağlamakta. Yapay zekâ uygulamaları, arama motoru sonuçlarını seçmekten müzik ve video önermeye ve arkadaş önerisi yapmaktan haber akışlarındaki yayınları sıralamaya kadar bu popülarite veya “etkileşim” sinyallerinden yoğun bir şekilde yararlanıyor.

Indiana Üniversitesi Enformatik ve Bilgisayar Bilimleri profesörü Filippe Menczer tarafından gerçekleştirilen bir araştırma ise sosyal medya ve haber öneri sistemleri gibi hemen hemen tüm web teknolojisi platformlarının güçlü bir şekilde “popülarite”ye eğilim gösterdiğini ortaya koydu.
Uygulamalar, arama motoru sorguları yerine etkileşime dayanan ipuçlarına göre yönlendirildiğinde, “popülerlik” tarafgirliği istenmeyen zararlı sonuçlara yol açabiliyor.
Facebook, Instagram, Twitter, YouTube ve TikTok gibi sosyal medya platformları, içeriği sıralamak ve tavsiye etme noktasında büyük ölçüde yapay zeka algoritmalarına dayanıyor. Bu algoritmalar, “beğenilerinizi”, yorumlarınızı ve paylaşımlarınızı yani etkileşimde bulunduğunuz içeriği girdi olarak ele almakta. Bu algoritmaların amacı insanların neleri beğendiğini bulmak ve bunların haber akışlarında en üst sırada yer almasını sağlamak.
Özünde bu makul görünüyor. İnsanlar güvenilir haberleri, uzman görüşlerini ve eğlenceli videoları beğendiklerinde algoritmaların bu kadar yüksek kaliteli içeriği tanımlaması oldukça yerinde. Ancak “kalabalıkların bilgeliği” popüler olanı tavsiye etmenin yüksek kaliteli içeriğin ortaya çıkacağına yardımcı olacağı şeklinde önemli bir varsayımda bulunmakta.
Bu varsayım, kalite ve popülerliği kullanarak öğeleri sıralayan bir algoritma incelenerek test edildi. Genel olarak, popülerlik yanlılığının içerik kalitesini düşürme olasılığının daha yüksek olduğu ortaya çıktı. Bunun nedeninin birkaç kişinin bir içeriğe maruz kalması durumunda etkileşimin güvenilir bir kalite göstergesi olmaması olarak düşünülüyor. Bu durumlarda, etkileşim “gürültülü” bir sinyal üretiyor ve algoritmanın bu ilk gürültüyü yükseltmesi muhtemel olarak değerlendiriliyor. Düşük kaliteli bir ürünün popülaritesi yeterince büyük olduğunda, popülerlik artmaya devam edecektir.
Biden, Facebook’a yüklendi: Aşıyla ilgili mezenformasyon insanları öldürüyor
Algoritmalar, etkileşim tarafgirliğinden etkilenen tek şey değil. İnsanlar da bu tarafgirlikten etkilenmekte. Bulgular bir kişinin çevrimiçi bir fikre ne kadar çok maruz kalırsa onu benimseme ve yeniden paylaşma olasılığının o kadar yüksek olduğunu ortaya koymakta. Sosyal medya insanlara bir içeriğin viral hale geldiğini söylediğinde, bilişsel önyargılar devreye giriyor ve buna ilgi göstermek ve paylaşmak için karşı konulmaz bir dürtü oluşuyor.
KALABALIKLAR HER ZAMAN AKILLICA KARARLAR VERMİYOR OLABİLİR
Yakın zamanda Fakey adlı bir “haber okuryazarlığı” uygulaması kullanılarak bir deney yapılmış. Bu, Facebook ve Twitter’ınki gibi bir haber akışını simüle eden bir laboratuvar tarafından geliştirilen bir oyun. Oyuncular, sahte haberlerden, popüler bilimden, aşırı partizan ve komplocu kaynaklardan ve ana kaynaklardan gelen güncel makalelerin bir karışımını görmekteler. Oyuncular güvenilir kaynaklardan gelen haberleri beğendiğinde ve paylaşım yaptıklarında ve güvenilirliği düşük haberleri işaretlediklerinde puan kazanıyorlar.
Araştırma sonunda oyuncuların, diğer birçok kullanıcının bu haberlerle etkileşim kurduklarında, oyuncuların düşük güvenilirlikteki kaynaklardan gelen haberleri beğenme veya paylaşma olasılıklarının daha yüksek olduğu ortaya çıktı. Bu durumun zafiyete yol açtığını söylemek zor değil.
Bu durumda Kalabalıkların bilgeliği tezi başarısız olmakta zira bu varsayım kalabalığın çeşitli ve bağımsız kaynaklardan oluştuğu fikrine dayanmakta. Bunun böyle olmamasının birkaç nedeni var.
Birincisi, insanların benzer insanlarla ilişki kurma eğilimi nedeniyle, çevrimiçi ortamlarında çeşitlilik az bulunan bir durum. İkincisi, birçok insan arkadaşlarından etkilenmekte. Ünlü bir deney, arkadaşlarınızın hangi müzik türünden hoşlandığını bilmenin kendi tercihlerinizi etkilediğini göstermekte.